Highlights from KDD 2020
The 26th SIGKDD Conference on Knowledge Discovery and Data Mining (KDD 2020), perhaps the most prestigious academic Data Science conference, took place last week. It was held entirely online, thanks to the travel restrictions brought by COVID-19. I watched many of the presentations and talked to people. Here I summarize what I learned.
Online Conferences
First of all, did the virtual format worked? Overall, I still prefer physical conferences, but there are positive aspects in the online version, notably:
- It is much cheaper. I had already spent a lot to go to AAAI 2020 last February, so I had not planned to attend KDD this year. Thanks to the much cheaper online format, however, I changed my plans and participated.
- In some ways, it is easier to talk to people. After all, anyone is just one message away within the conference app. I had very productive conversations and learned a lot in this manner. In fact, I was the third most chatty person.
As for the negative aspects:
- It is not so easy to prioritize the conference when you are in your natural environment, where work and home duties are much closer. So whatever stressors you have you your life, they remain with you.
- The coffee breaks do not work because you aren’t really synchronized with other participants. You can’t see them and you don’t walk out of a room with them.
- Casual conversation is difficult, and no one will say anything that might get them in trouble, since everything is recorded.
- Exhibitors and sponsors probably suffered. A “virtual booth” seems far less effective, at least in the format that was used.
- It simply is not as fun. We are three-dimensional creatures, space is important and traveling clears the mind, so in a sense this was all quite inhuman.
In summary, I learned a lot and kept my money, which is great, but I would still prefer to travel to the next edition! That said, note that AAAI 2021 will also be held virtually next Februrary, so it should be easy and cheap to attend.
Finally, it is worth noting that there is considerable space for improving virtual experience. The time has come for some proper online conference tool. The ones used by KDD (Vfairs and Whova) got the job done, but are way too imperfect to make this a sustainable format in my opinion. Surely some entrepreneur will take the bait.
Industry and Data Science
There were many presentations, panels and conversations regarding the relationship between academia, research and industrial practice.
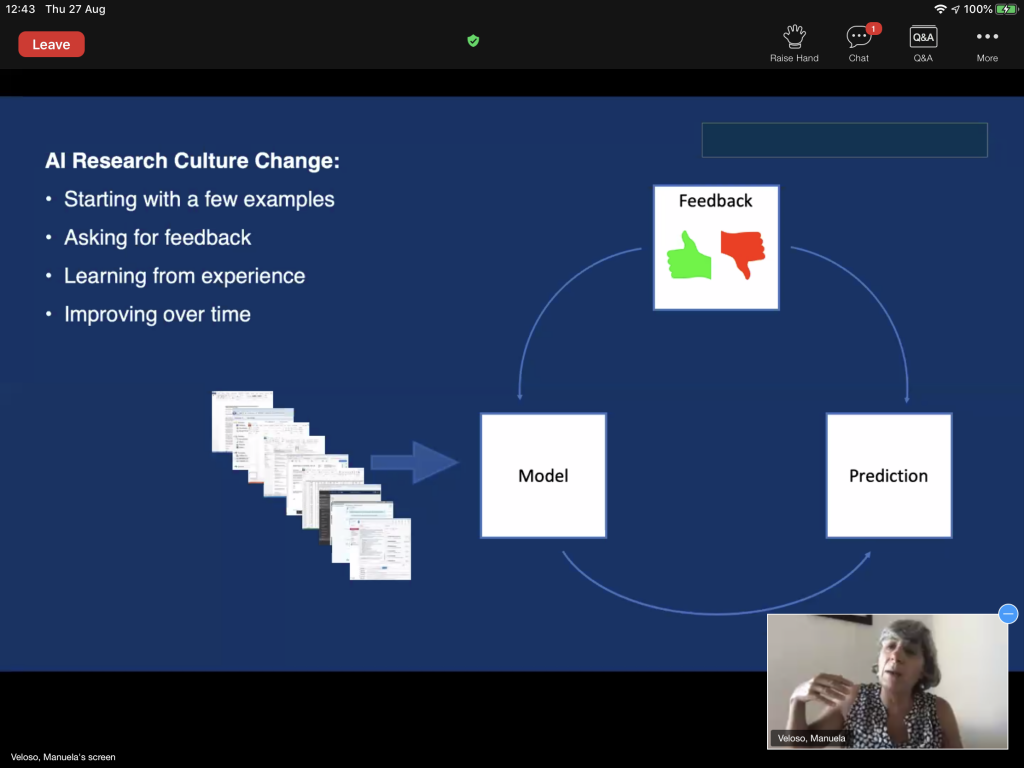
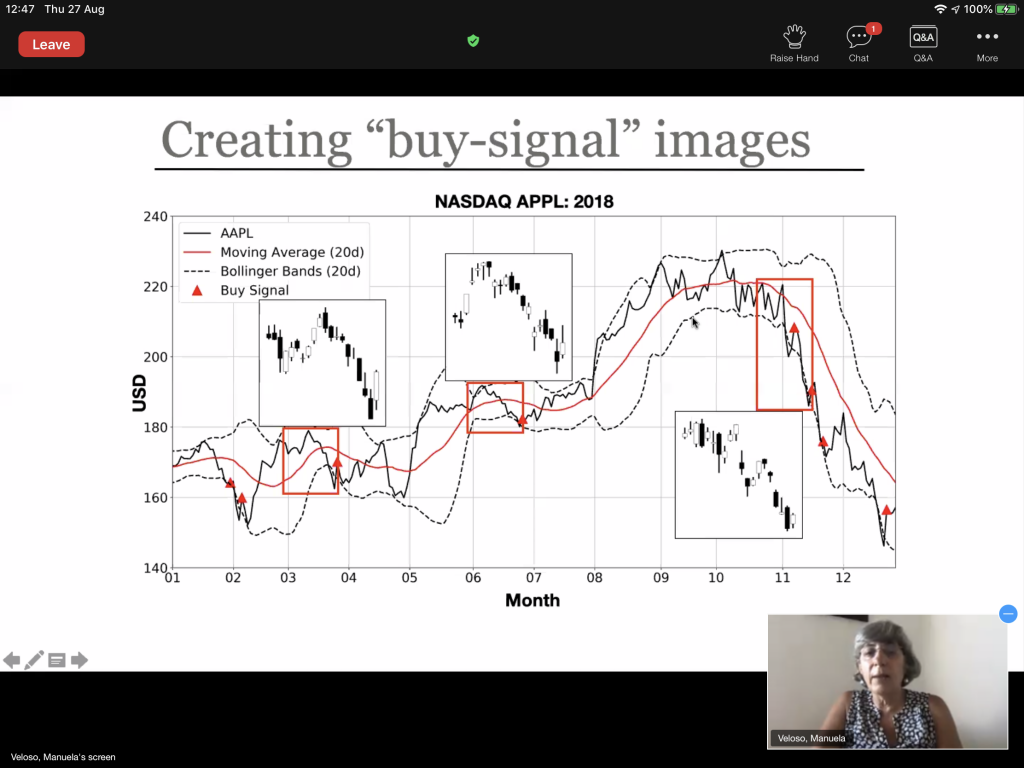
- Manuela Veloso‘s talk on AI for intelligent financial services was to me one of the most insightful. Having spent decades in academia and recently moved to J.P. Morgan as Head of AI Research, she is in a privileged position to comment on the potential and challenges of bringing AI research thinking into more traditional companies. Three main takeaways for Data Scientists in this respect:
- Act as a scientist, even if that is not business as usual for the company. There’s no point in hiring you if they will not let you work, so take a stand.
- Executive leadership trust and support are essential. You won’t be able to work properly otherwise. This means, for example, not deploying prototypes in production before they are ready, even if they are already impressive (see her Mondrian project).
- In return, recognize that business people know the business, not you (initially anyway). We should all learn with each other. Otherwise, it doesn’t work.
- Some very interesting research she talked about:
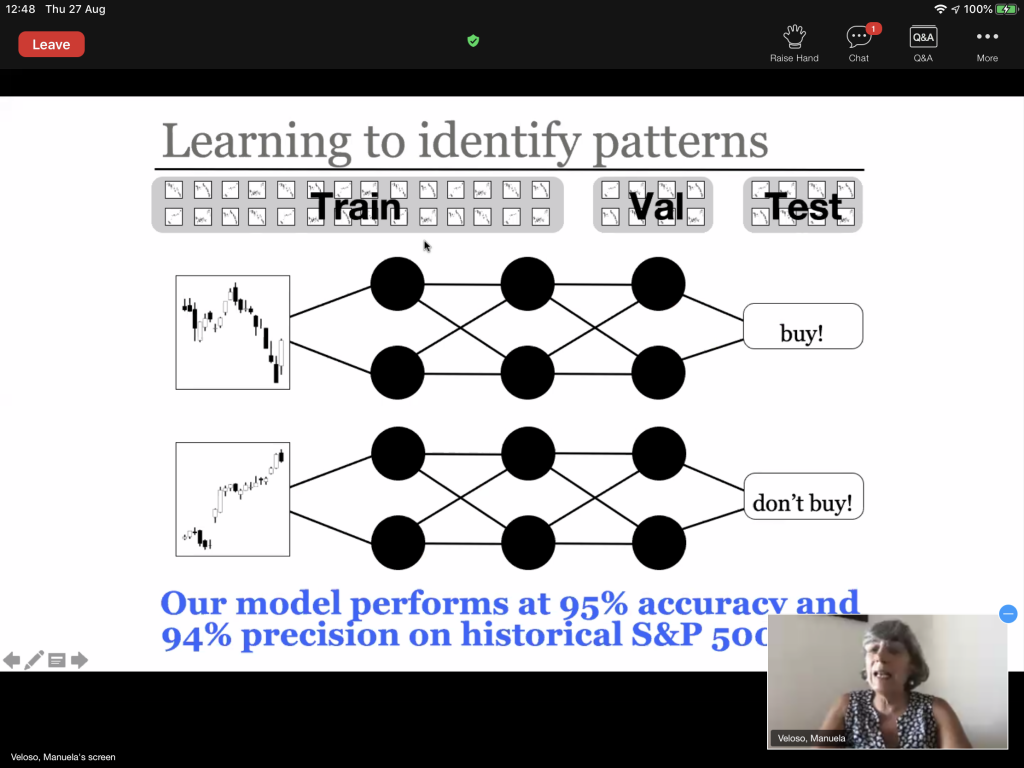
- Mondrian, a project for trading recommendations based on images (see below in Time Series section).
- Synthetic data generation (see below in Time Series section).
- AI pptX, an automated generator of PowerPoint presentations. I guess this is the ultimate business application for AI.
- Students are educated through well-defined problems, but that almost never happens in practice. As a result, they are seldom ready to face industry challenges. I might add that Kaggle-style training has the same problem.
- If a Data Scientist spends 50% of his/her time cleaning data, he/she is lucky. Unfortunately, and as we should all know by now, data quality and access problems are usually inescapable and often underestimated.
- One of the hardest things is to create good metrics. In fact, “metric/goal/objective function engineering” is something to be taken quite seriously. See also the tutorial on User Metrics and the paper A dirty dozen: twelve common metric interpretation pitfalls in online controlled experiments.
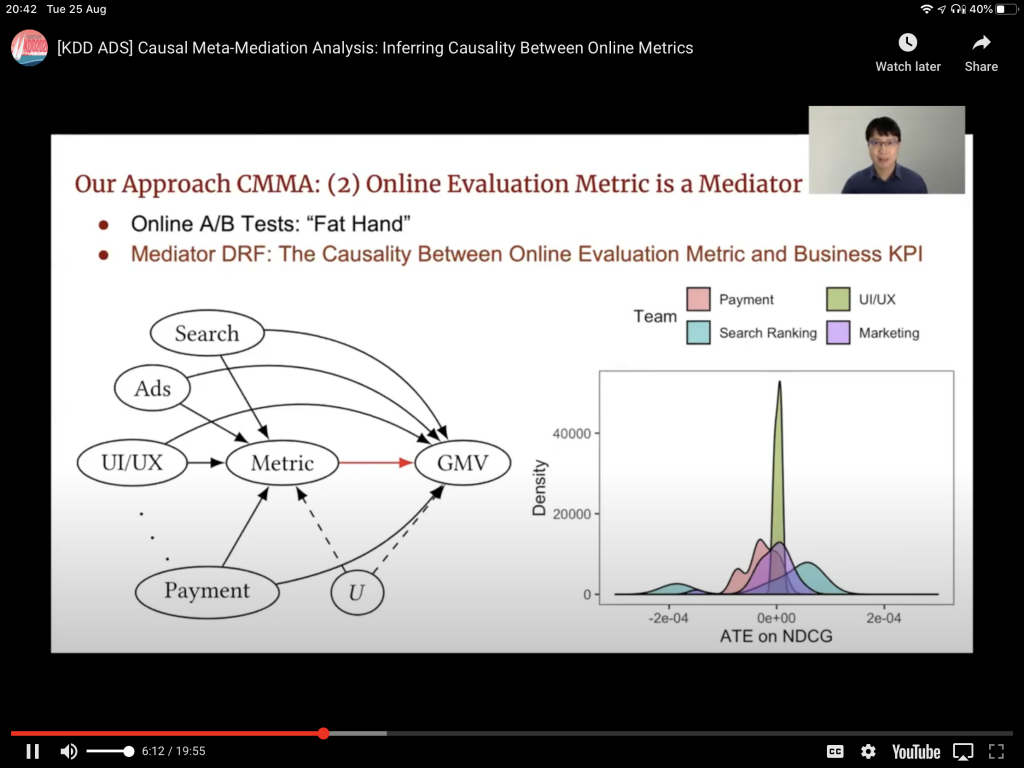
- See Causal Meta-Mediation Analysis Inferring Dose-Response Function From Summary Statistics of Many Randomized Experiments. See also Data-Driven Metric Development for Online Controlled Experiments: Seven Lessons Learned.
- Although experimentation is the best way to optimize prices, this is not always possible for either business or technical limitations. Therefore, it is important to have techiques to do so through causal inference only. See the case of Walmart in Price Investment using Prescriptive Analytics and Optimization in Retail.
I talked to some other participants in the chat rooms and these conversations gave me some important insights, such as:
- A lot of companies out there, even well-established ones, have no proper Data Science methodology. It is often ad-hoc, unsystematic, crazy work.
- One solution is to define a strategy first, and then systematically execute it. This is what I am doing at my current management position and what others recommended as well. Everybody seems to basically have the same advice: have a guiding technical strategy, work incrementally, ensure users are observed, heard and involved, take feedback, repeat and improve.
- Price optimization through experimentation can bring huge profits, but it is challenging to convince business stakeholders to pursue this strategy.




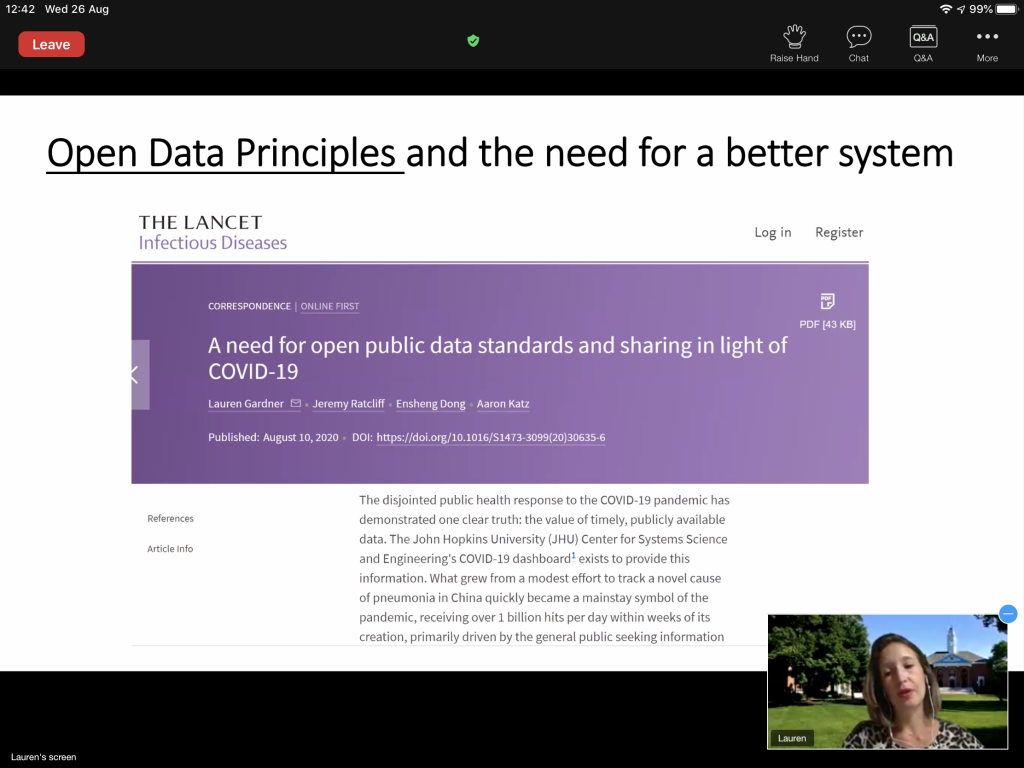
Recommender Systems and Information Retrieval
Recommender systems are really at the center of our lives these days. At least in my life anyway, now that forced home-office makes me order way more food through apps than I used to just a few months ago. Their presence in the conference reflects this growing importance. There are several related themes as well that in a way or another are connected to recommendations (e.g., Reinforcement Learning).
- There was a great tutorial on Advances in Recommender Systems.
- There was an extensive tutorial on Learning by Exploration, essentially covering techniques for multi-armed bandits Reinforcement Learning. I learned about, for instance:
- There are multi-agent versions of the multi-armed bandits problem.
- Confidence intervals can be exploited to hypothesize about best and worst-case scenarios, which allows for optimization during exploration (i.e., Upper-Confidence Bound – UCB – algorihtm and variants).
- CUSUM is a classical change detection technique, which can be useful to navigate non-stationary environments. There a number of variants and alternatives based on confidence bounds as well.
- One idea I had: maybe this can be used to detect regime changes in algorithmic trading.
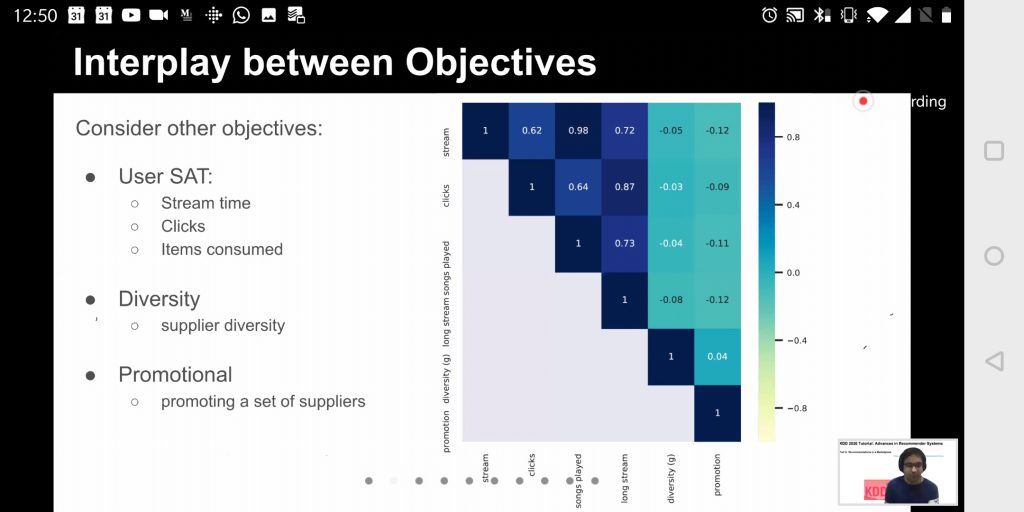
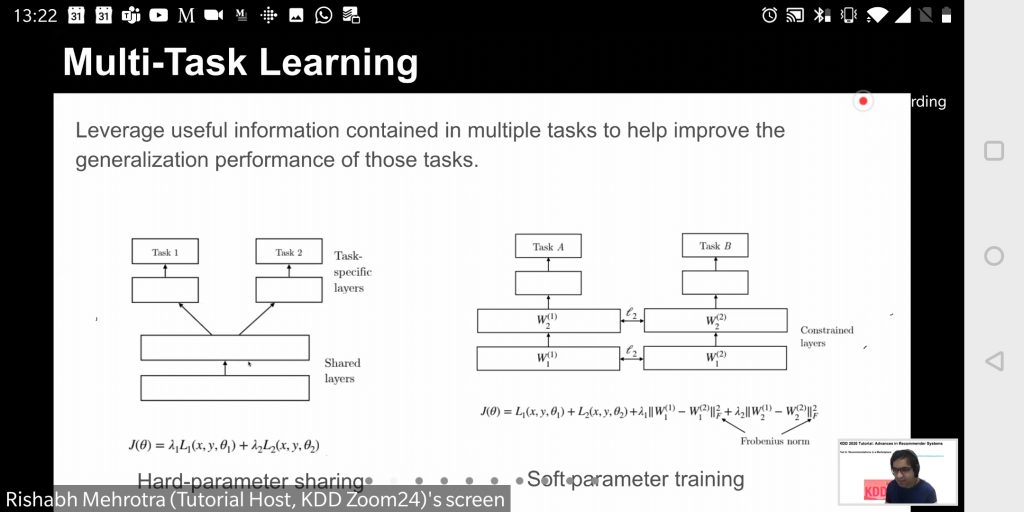
- Traditional recommender systems only take the user’s well-being into account. However, there is a growing number of application in which this is not at all enough. So Multi-objective, multi-task, recommender systems must be devised. Consider, for example, any online market place, in which we have to balance the interests of three groups: buyers, sellers and the market itself.
- Ranking presents subtle problems. For instance, in a music recommender system, many artists might have very high scores. So small differences might cause a huge impact, which makes no sense, since these differences might be simply due to noise. The top-ranked artist is benefited of course, but everyone else looses. The artists that are as good as the top one won’t be found. Fans will not enjoy more varied music. And the platform itself will be more fragile, depending on a smaller number of elite artists.
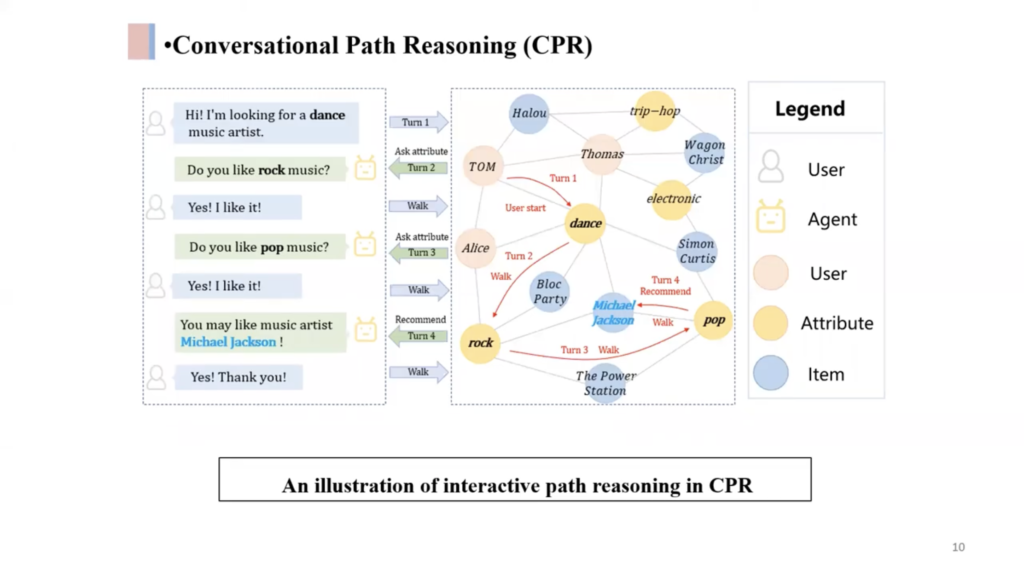
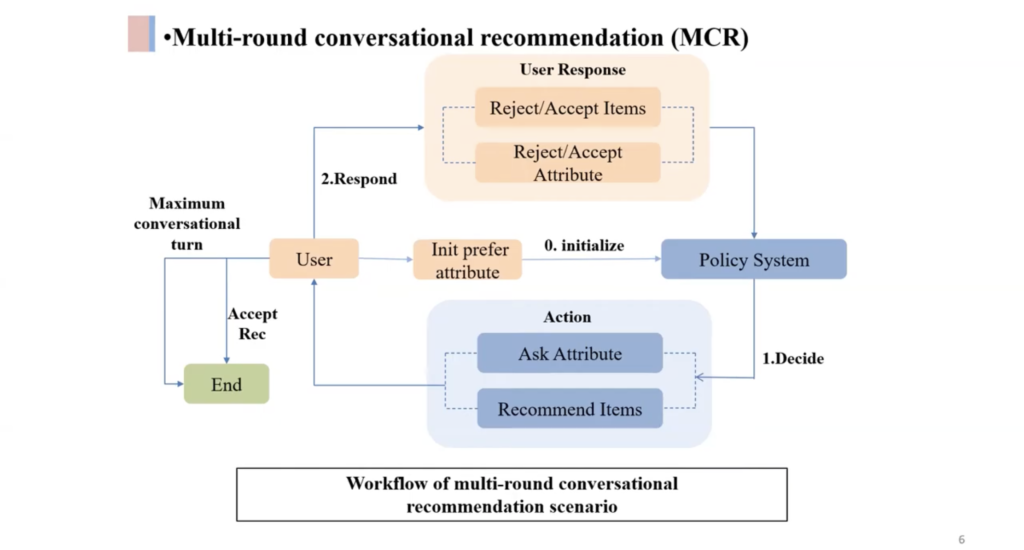
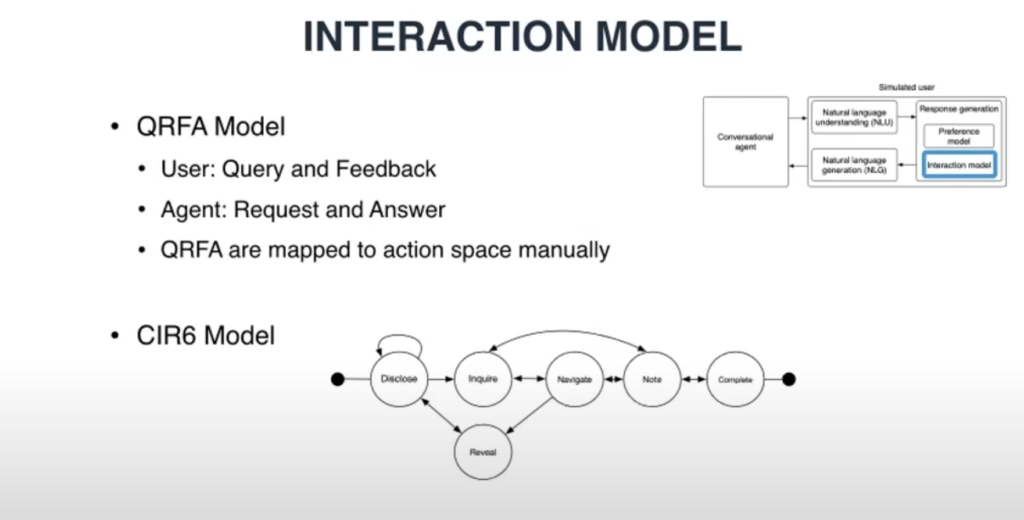
- User modeling and Conversational Recommender Systems is a very interesting topic:
- Users can be simulated in order to evaluate the quality recommendations. See Evaluating Conversational Recommender Systems via User Simulation.
- User preferences can be modeled as graphs, which allows for better recommendations. See Interactive Path Reasoning on Graph for Conversational Recommendation and Improving Conversational Recommender Systems via Knowledge Graph based Semantic Fusion,
- Language embeddings can be used to improve search results. On Facebook, for instance, these can incorporate structural information about the social graph. See Embedding-based Retrieval in Facebook Search. On Google, customizing the embedding length has improved results and resource usage. See Neural Input Search for Large Scale Recommendation Models.
- Crowd-sourcing can be made more efficient by improving measures of confidence. See CLARA: Confidence of Labels and Raters.
- The behavior and context of users can help in providing more relevant recommendations by accounting for how the various elements interact. See Calendar Graph Neural Networks for Modeling Time Structures in Spatiotemporal User Behaviors and Learning to Cluster Documents into Workspaces Using Large Scale Activity Logs.
- Business KPIs do not follow easily from Machine Learning validation metrics. It is wise to find a way to connect both, so that systems can be developed and validated in such a way that the final business outcome is also impacted in a more predictable manner. This is tricky because it is difficult to isolate the causal factors involved. However, given many and varied executions of the system to be optimized, it is doable. See Causal Meta-Mediation Analysis Inferring Dose-Response Function From Summary Statistics of Many Randomized Experiments.
- It is possible to transfer knowledge from common user behaviors to tail (i.e., rare or uncommon) behaviors, which is useful, for instance, to address the cold-start problem. See Learning Transferrable Parameters for Long-tailed Sequential User Behavior Modeling.




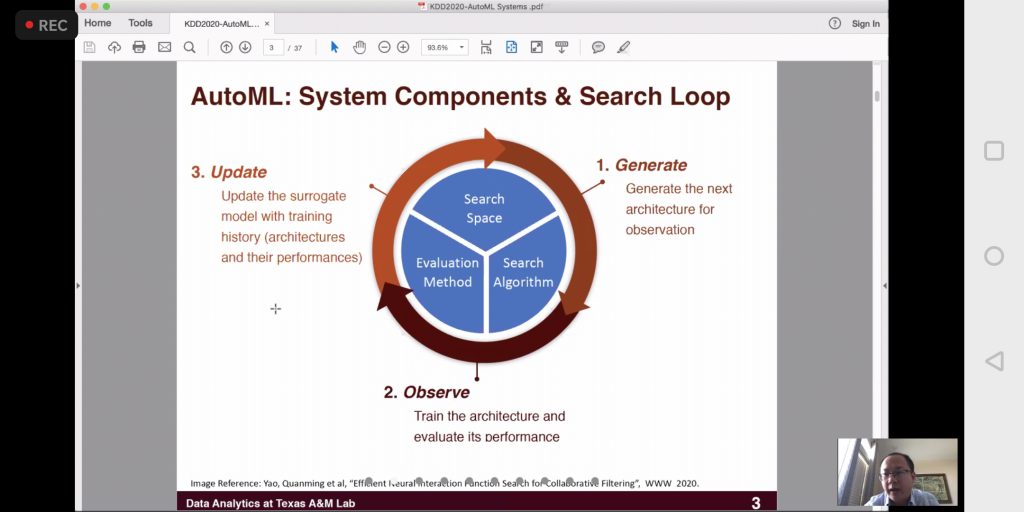
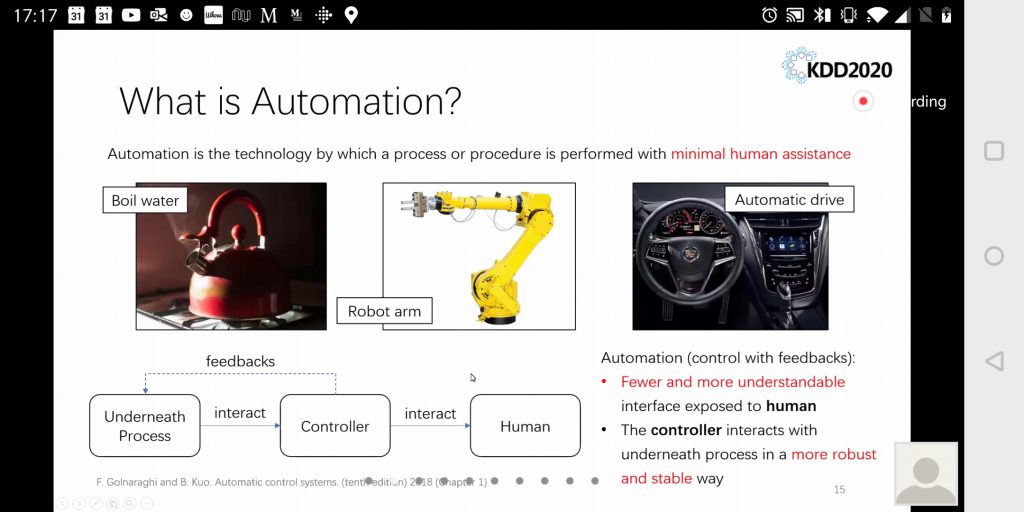
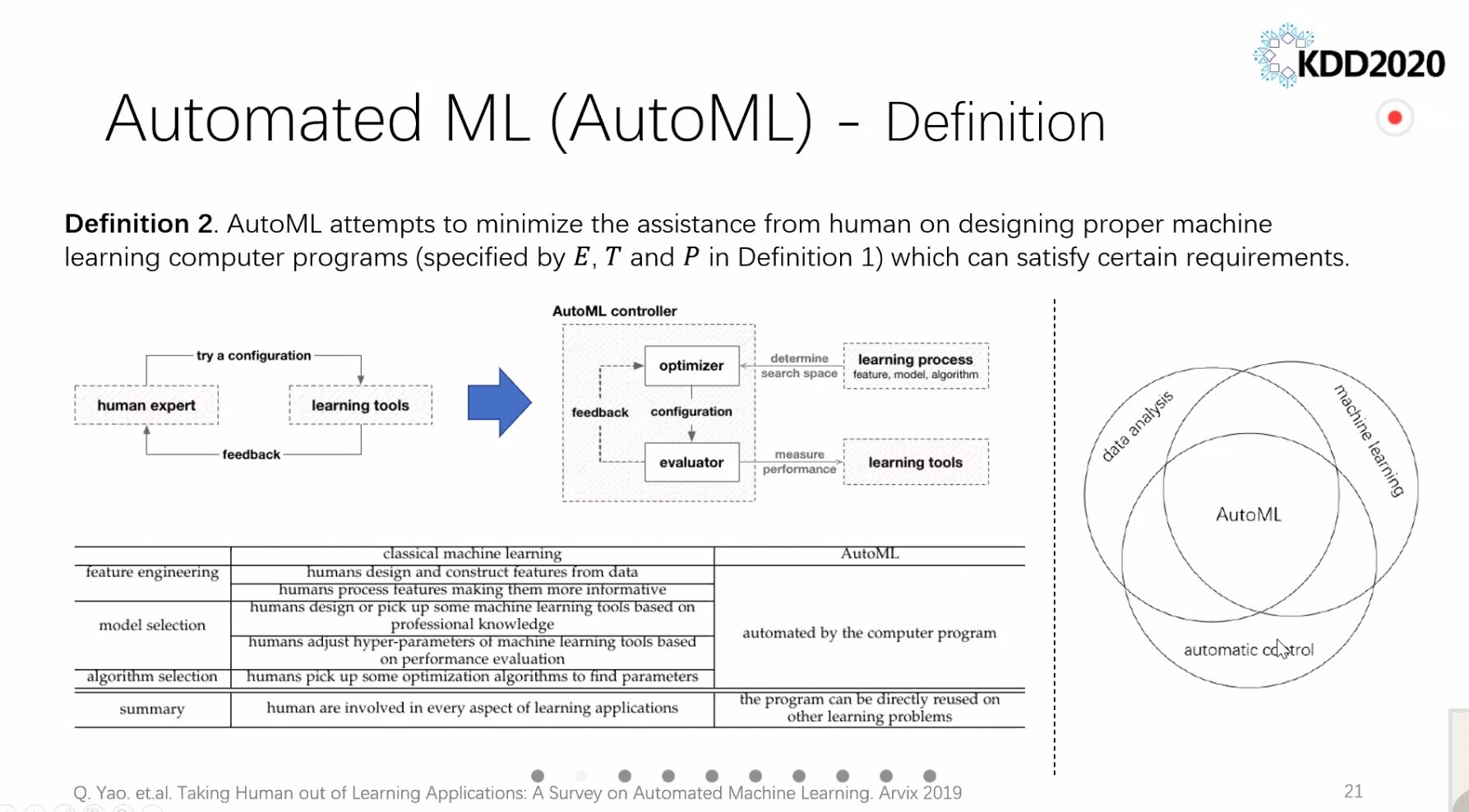
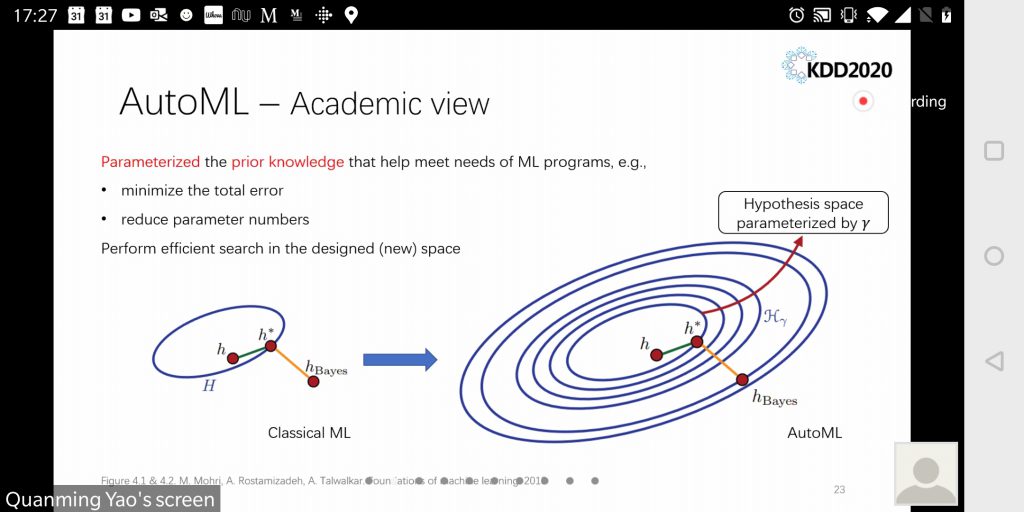
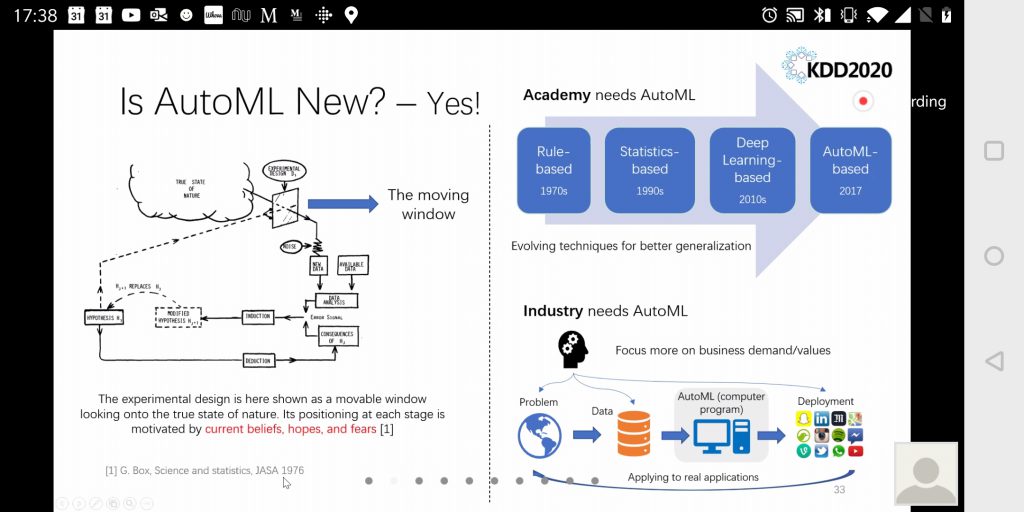
AutoML
Automatic Machine Learning, or AutoML, got a lot of attention too.
- There was a workshop dedicated to the theme, The Fourth International Workshop on Automation in Machine Learning.
- There was a very informative AutoML tutorial by Microsoft. In particular, we played a bit with Azure AutoML, which is really nice and has both a graphical version through the Web and a Python SDK for programmatic use. I suggest you take a look at the new Microsoft Azure Machine Learning Studio to try this out.
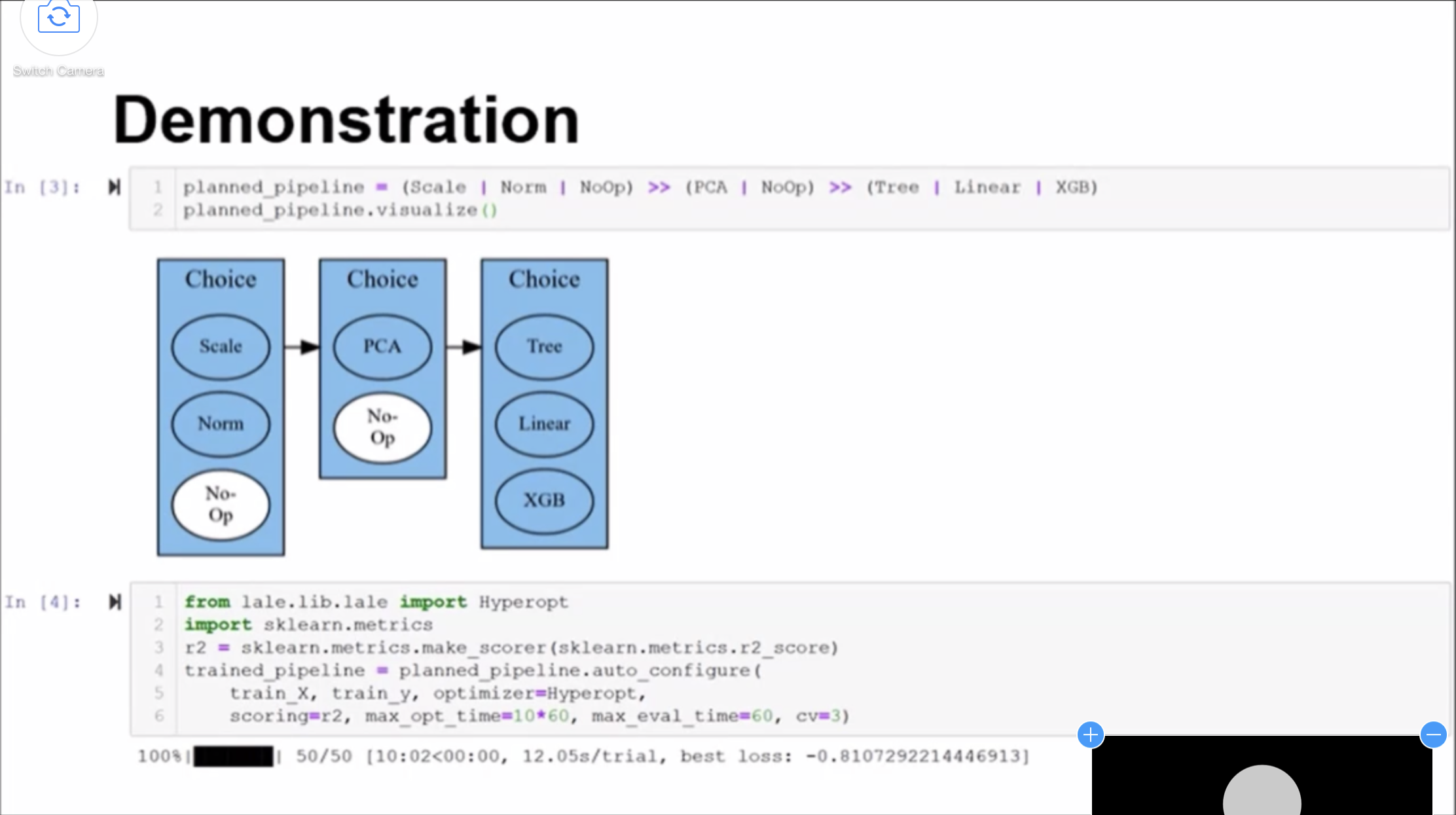
- Lale is a very interesting AutoML library by IBM. What I liked most about it is the fact that we can define a structure to be explored, and then the library handles the necessary experiments to determine the best composition. See Lale: Consistent Automated Machine Learning. This work reminded a lot of my own paper on user interface optimization, see User Interface Optimization using Genetic Programming with an Application to Landing Pages.
- Other AutoML platforms and tools:
- Reinforcement Learning can be used to automatically create Machine Learning pipelines in a much more efficient way. See DeepLine: AutoML Tool for Pipelines Generation using Deep Reinforcement Learning and Hierarchical Actions Filtering. Se also the paper AlphaD3M: Machine Learning Pipeline Synthesis.
- I got the feeling that there is some kind of rivalry between “AutoML people” and “meta-learning people”. My guess is that the intuition that moves both communities is the same, but their practical motivations are not, hence the difference. AutoML seems to be more industry-oriented, for instance.
- No, AutoML will not replace Data Scientists. It will just make Data Scientists more productive, handle the boring stuff and boilerplate code. Just like modern programming languages and compilers improved the lives of programmers. Python or Java are not “AutoProgramming”, despite the fact that their programs are automatically translated into machine code. People were amazed that even participants of KDD and similar venues, who should know better, often feared being made obsolete! Also, contrary to popular belief, The Singularity is not coming anytime soon. Rest assured we are all too incompetent for that and have way more pressing issues at the moment.
- The overall topic of human-computer cooperation in Machine Learning was to theme of a whole workshop, The 1st Workshop on Data Science with Human in the Loop (DaSH). Perhaps surprisingly, if we could properly combine human and machine intelligence, we could actually have more automated learning systems, and less total human labor. A high ROI, assuming we are not foolish in our investments, of course.




Time Series
I really like time series. They are everywhere and their analyses can help in many different ways, from fighting a pandemic to getting rich in the stock market.
- I was glad there was a dedicated workshop, the 6th Workshop on Mining and Learning from Time Series. I had some very productive conversations with members of this community, including the very helpful Rose Yu, who suggested some of the references below.
- Temporal Convolutional Networks (TCN) is a topic that came up a lot.
- Synthetic time series generation was one topic that started to appear, though not much.
- I asked some people about it, but for most it was a rather obscure topic.
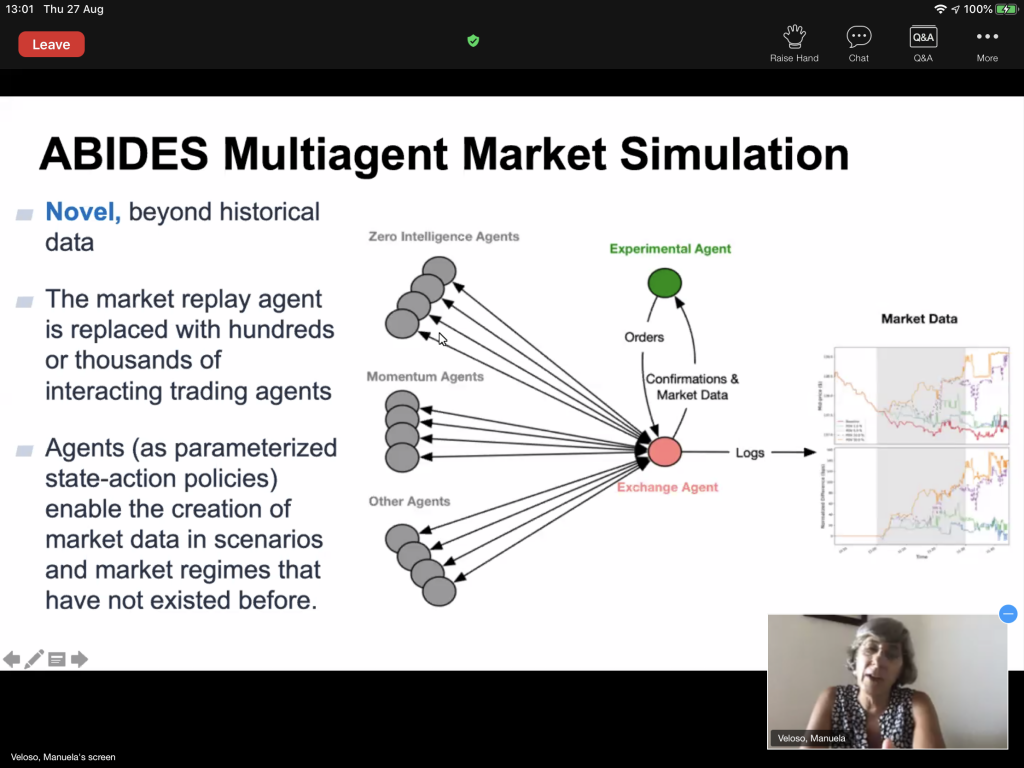
- Thankfully, it turns out that it is a very important topic to J.P. Morgan and I learned a lot about it during Manuela Veloso’s talk. In particular, they have a complex stock market simulator to create realistic, but never seen, scenarios. One important aspect of this kind of work is that the generated series should have similar statistical properties to the real ones.
- I was also told about the upcoming NeurIPS challenge on adversarial time series generation.
- My own open-source synthetic time series generation project, called TimeBlender, is an attempt to create a programmatic and compositional tool, to blend human and data insights.
- I was told that combining these programmatic specifications with learning from observation has a novel taste to it. Maybe I can get a paper out of this at some point after all.
- A somewhat related paper on Programmatic Reinforcement Learning, Imitation-Projected Programmatic Reinforcement Learning.
- Other related papers:
- Anomaly detection in time series is very relevant for aviation safety. We had a nice talk on this topic by Nikunj Oza, which showed, in particular, an active learning strategy for anomaly detection.
- When asked about simulated scenarios to train the model better, Nikunj told us that it was a very good idea, but very hard as well. It is difficult to come up with realistic anomalies that are not obvious.
- It is possible to embed a driver’s representation in a vector using just driving behavior. See Driver2vec: Driver Identification from Automotive Data.
- Here’s how to graphically interpret temporal neural networks through visualization: Interpreting Deep Temporal Neural Networks by Selective Visualization of Internally Activated Nodes.
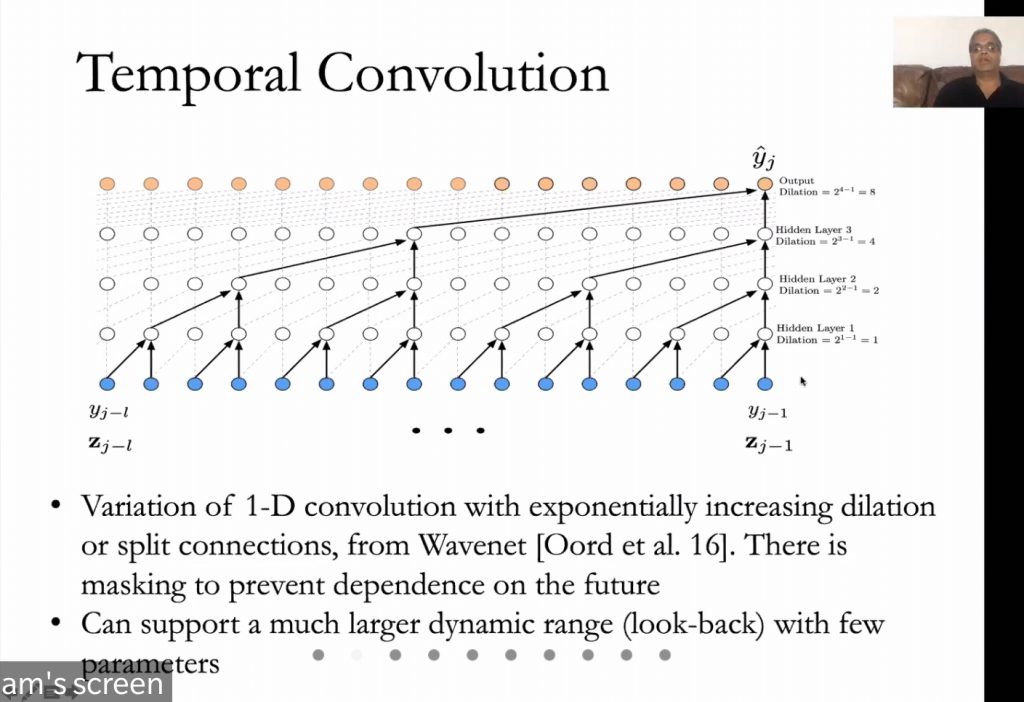
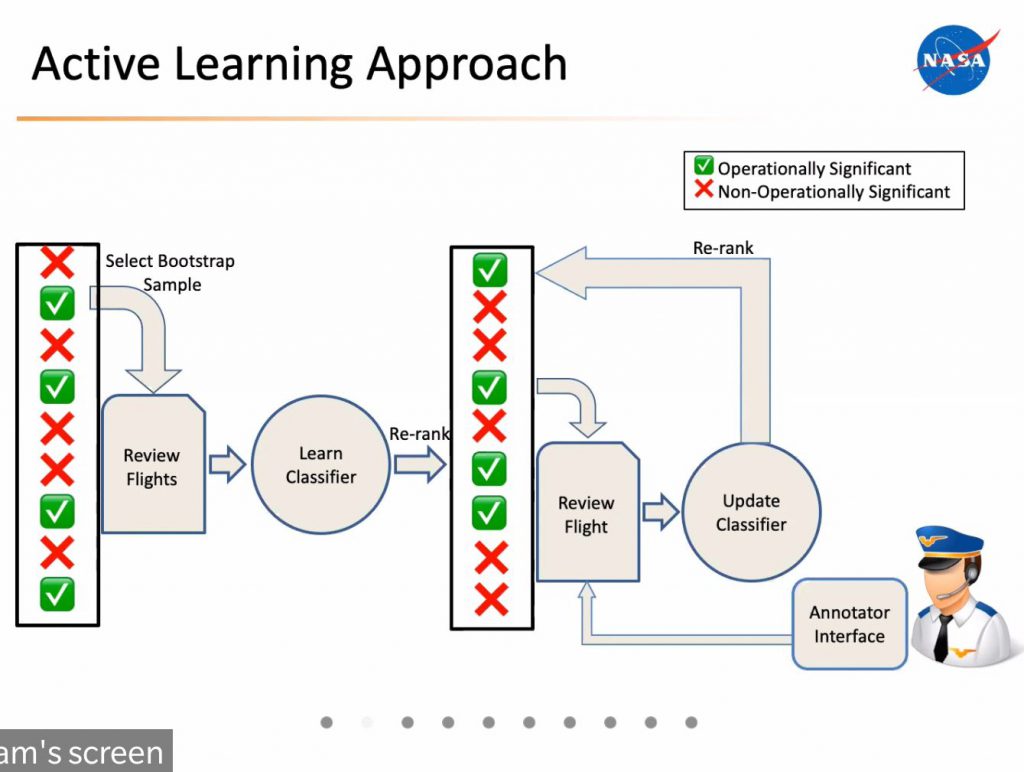
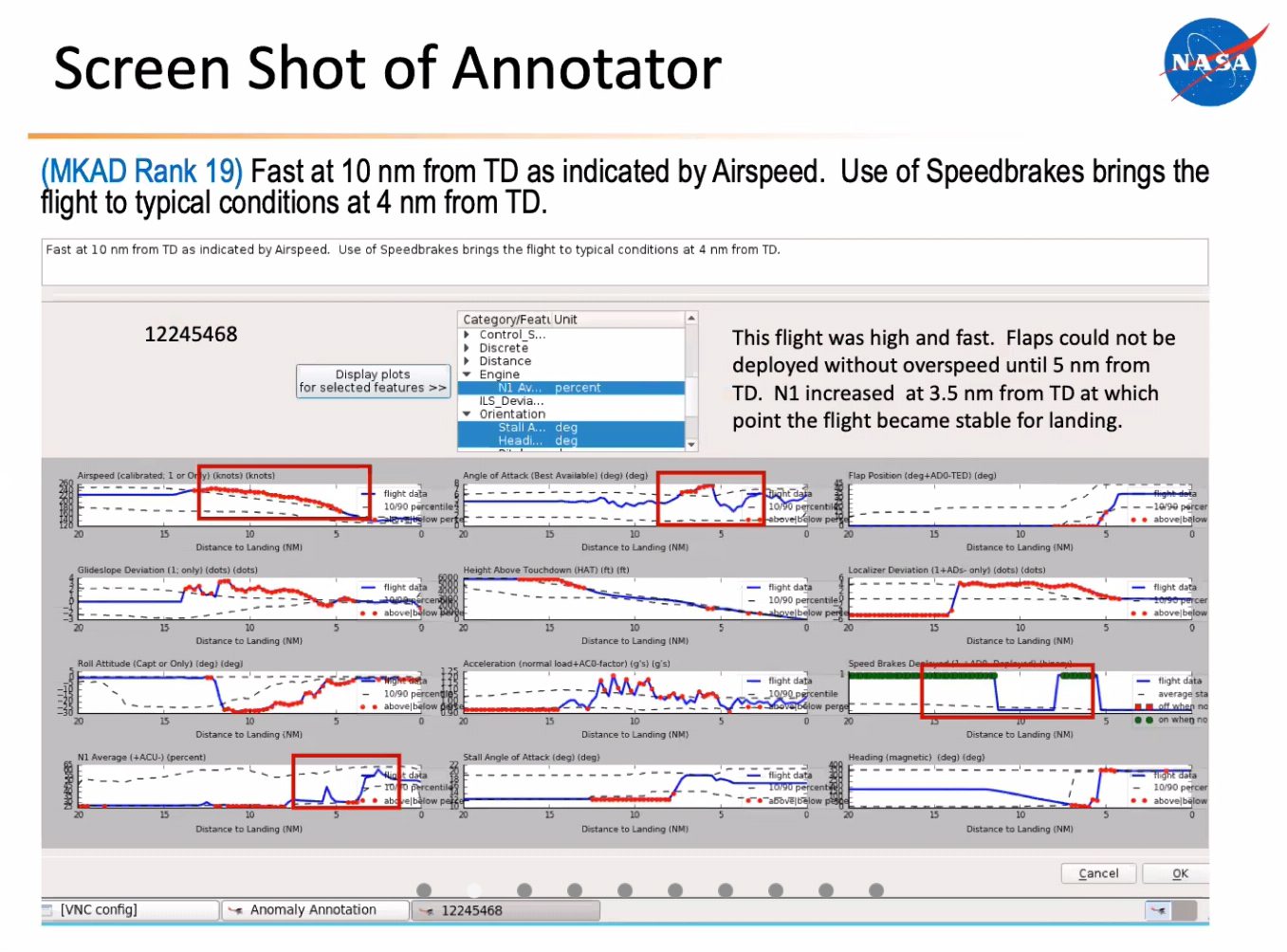
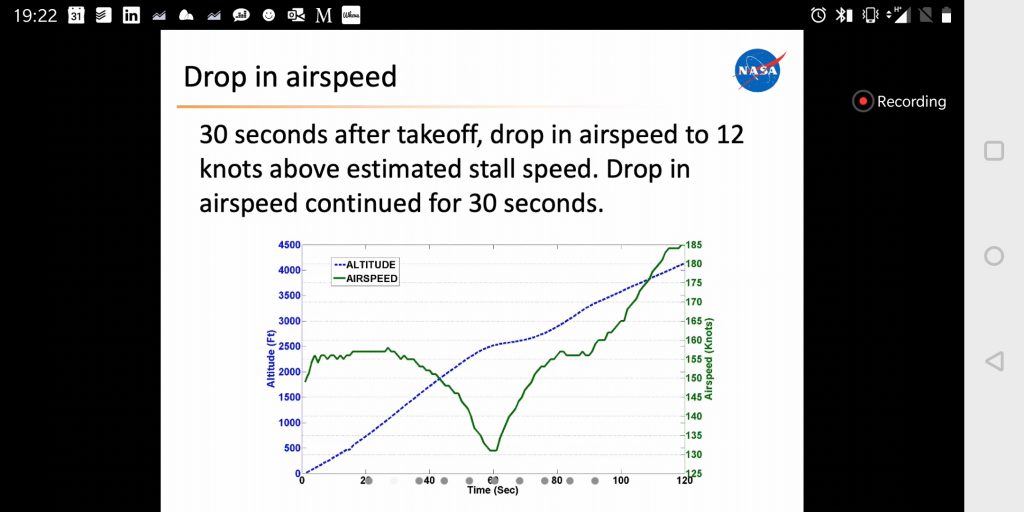

Natural Language Processing
NLP has enjoyed considerable progress over the last few years, so of course it was well represented here. In particular:
- Embeddings are everywhere, not only in NLP.
- The text summarization tutorial presented the basics of Transformers and latest techniques for summarization, based for instance on the BERT language model though BertSum.
- Summarization can be either extractive (i.e., select some sentences) or abstractive (i.e., paraphrases the text).
- The task can be seen as a form of translation from and to the same language, but with a length constraint.
- Some useful data sources for summarization training, because their articles contain human-crafted summaries: CNN, Daily Mail, The New York Times, XSum.
- Microsoft hosts a very nice repository with “easy” to use NLP recipes for different types of problems. This includes the summarization techniques mentioned above.
Healthcare and COVID-19
There were also various workshops dedicated to healthcare, but I could not attend them. What I did pay attention to was some of the COVID-19 talks.
- Healthcare-related workshops if you feel like looking through their content:
- Workshop on Applied Data Science for Healthcare
- Knowledge-infused Mining and Learning
- Designing AI in support of Good Mental Health. Yes, I’m sure I could have benefited. Yes, I know it is a bad joke.
- Unsurprisingly, COVID-19 was extensively discussed.
- A lot of smart and well-intentioned people are working in modeling the pandemic. I’m afraid, however, that these results, including my own unpublished model, can’t really be trusted yet. At best, they must be interpreted by experts in the context of their domain knowledge and as support for other reasoning methods. The reason is that there’s no way to properly validate these models. They are constantly adapted to account for the latest facts, which means their predictions cannot go to far into the future (i.e., they are not validated beyond short-term predictions). However, they are helping us to learn a lot about computational modeling, and hopefully at some point we will have modern and reliable epidemic models for the next pandemic.
- I also think that since there is no strict, formal, control of predictions, it is actually hard to check which models are really working.